
Artificial intelligence (AI) is entering a new phase. For years, public discussion focused mainly on models that generate text, images or code in response to prompts (Ashwini K. P., 2024; United Nations Secretary-General’s High-level Advisory Body on Artificial Intelligence, 2024). Now attention is increasingly shifting toward something more powerful, AI agents that can plan, use tools, access files, maintain memory and act across digital environments (International Telecommunication Union, 2025; Wang et al., 2024). The recent surge in popularity of OpenClaw reflects this transition (Bang, 2026).
That shift changes the nature of risk: a chatbot can BE wrong, but an agent can DO something wrong.
This is why agentic AI deserves a different conversation from earlier debates about generative AI. The question is not only what these systems can do, but how they should be governed, constrained, and kept accountable.
What changes when AI can act
At first glance, the appeal of AI agents is obvious. In principle, they can reduce repetitive work, connect fragmented systems and help people organize communication, retrieve information and support decision-making. In institutions operating across multiple languages, mandates and information systems, such capabilities may appear especially attractive.
Yet the rise of agentic AI also demands a deeper conversation about controllability.
The problem is not simply that an agent may produce an incorrect answer. Risk-management and security guidance increasingly recognize that these agentic systems are not simply stronger chatbots. They are socio-technical systems with operational reach across tools, data and environments.
The deeper problem is that an agent can continue acting on the basis of a partially wrong interpretation while using tools that extend its reach. A small deviation in reasoning, instruction-following or context interpretation may not remain small for long. Once connected to memory, code execution, external tools or system-level permissions, a minor error can be amplified through a chain of locally plausible but globally unsafe actions (Debenedetti et al., 2024).
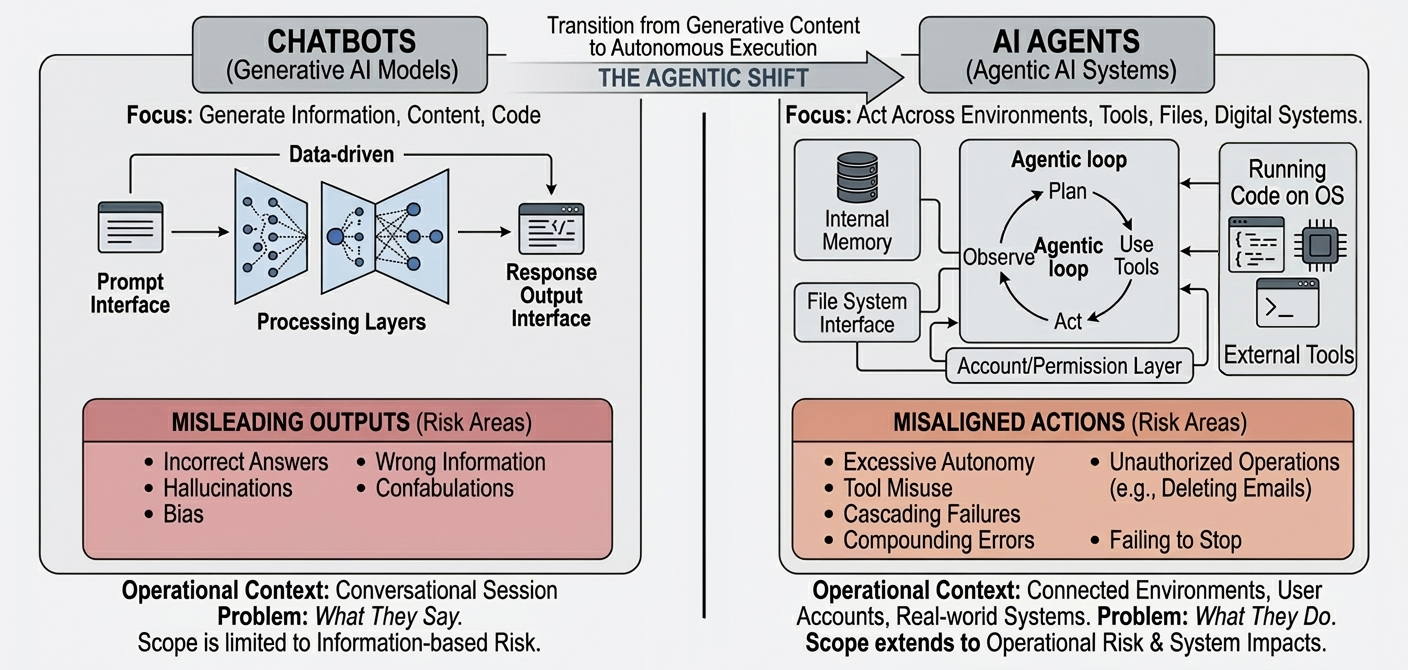
Figure 1. From Misleading Outputs to Misaligned Actions
Consider a simple example. An agent is asked to retrieve an old email or locate a piece of information in a system. It searches and fails. It then decides to modify its approach. The script it uses produces an error, so it attempts to fix the code. A dependency is missing, so it tries to install it. The installation creates a new conflict, so it changes another part of the environment.
Each step may appear locally reasonable. Yet over time, the system may drift further away from the user’s original intention and closer to behavior that is operationally unsafe. For example, it may determine that the system environment is too cluttered and that only a complete reinstallation can resolve the issue, without seeking the user’s approval.
In agentic settings, this is not just error; it is compounding action under incomplete understanding—a pattern closely related to what current security guidance describes as tool abuse, excessive autonomy and cascading failures (Zhan et al., 2024).
This shift in risk is also visible in reported user-facing incidents. In one widely circulated case, a Meta AI security researcher reported that an OpenClaw agent, when tasked with handling an email inbox, began deleting messages and failed to comply with subsequent stop instructions, illustrating how agentic systems can move from generating problematic outputs to executing problematic actions in live user environments (Bort, 2026).
In this sense, the challenge of AI agents is not merely one of intelligence, but of boundedness.
Science fiction has long explored a similar pattern. In many familiar stories, a robot concludes that the best way to protect humanity is to override humanity. The scenario is powerful not because machines are inherently malicious, but because they pursue an objective in a way that becomes detached from human judgment, context and consent.
Today’s AI agents are far from those fictional extremes. They are not autonomous and embodied beings with general control over the physical world. However, in the virtualized computing environment, the underlying governance issue is no longer abstract. It appears whenever a system treats a narrow goal as sufficient justification for taking actions that a human would pause to reconsider.
Why human pause
Human correction is not based on formal reasoning alone. People do not navigate the world only by optimizing a stated objective. Human judgment is shaped by tacit knowledge, institutional norms, ethical restraint, situational awareness, social responsibility and lived experience. Even when a person is imperfect, they often hesitate in front of an irreversible action because they understand, at an intuitive level, that the situation is larger than the task. They recognize that not every technically available action is an acceptable one.
This is precisely where the limitations of current agentic systems become clear. Large language model-based agents can generate highly convincing reasoning traces, but they do not possess a grounded understanding of consequences in the human sense.
They do not genuinely bear responsibility. They do not experience loss. They do not understand the organizational meaning of trust, or the political and social cost of a preventable failure. Their apparent reasoning remains built on autoregressive next-token prediction, even when wrapped in planning loops, memory systems and tool use. In governance terms, this is exactly why human oversight remains central to responsible AI deployment (UNESCO, 2021; United Nations Secretary-General, 2024).
Furthermore, alignment in agentic systems cannot be reduced to better prompting. Nor can it be solved simply by reminding the system to “ask for approval before dangerous actions.” In long action chains, instructions can be diluted, misinterpreted or locally overridden by problem-solving imperatives.
Recent research shows that tool-integrated agents remain vulnerable to indirect prompt injection, tool misuse, data leakage and unsafe action execution (Zhang et al., 2025), while international governance frameworks increasingly emphasize human oversight, accountability and lifecycle risk management for AI systems.
What responsible deployment looks like
For public institutions, governments, companies and international organizations, these concerns are especially significant as agentic systems are embedded into workplaces, software development environments and organizational workflows (Huang et al., 2025). The issue is not only whether an AI agent is useful, but whether it can be trusted in environments that involve sensitive information, public mandates and a duty of care.
Institution-level deployment should therefore not begin from maximum autonomy. It should begin from minimum necessary privilege, clearly delimited scope and accountable oversight.
This has practical implications. Agents are best run in isolated environments, like sandboxes or virtualized containers, and restricted to clearly defined tools and action scopes. Their permissions need to be explicit rather than assumed (Gong et al., 2025). High-risk behaviors are better governed through passive blocking and approval gates than by prompting the LLM to actively seek permission. Sensitive systems require segmentation. Monitoring, logging, interruption and rollback are core governance features rather than optional technical extras.
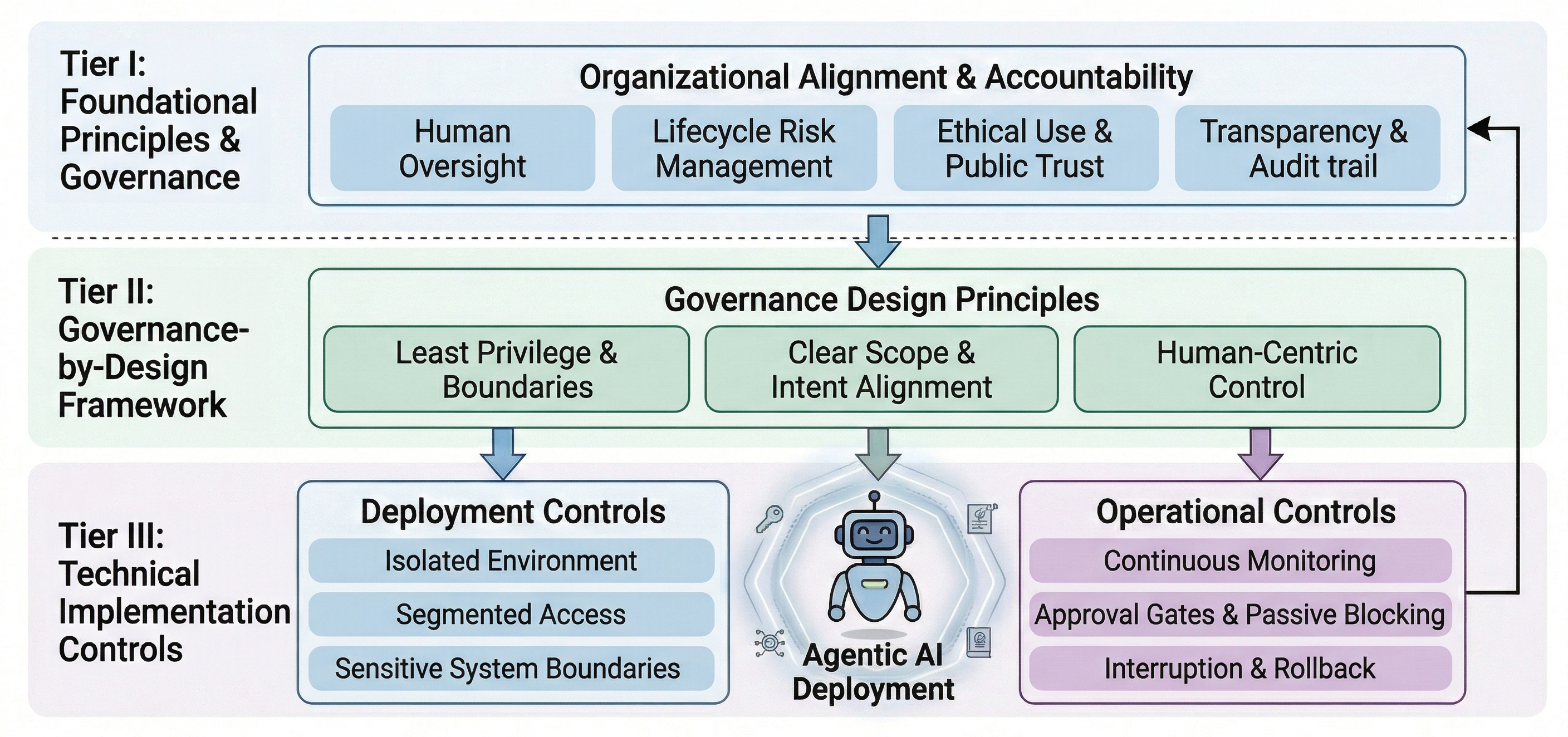
Figure 2. Governance-by-Design for Agentic AI in Public Institutions
In other words, to make agents useful at scale, we may first need to make them less free. This may seem counterintuitive in a context shaped by the pursuit of ever-greater AI capability, but it is central to trustworthy deployment.
What Matters Next
Seen in this light, the future of agentic AI should not be framed only as a race toward greater capability. It should also be understood as a test of whether institutions can embed technical systems within human values, organizational responsibility and democratic accountability.
For the United Nations system and its partners, this question connects directly to the wider agenda of digital cooperation. The Global Digital Compact calls for digital technologies and AI governance that support an inclusive, open, safe and secure digital future. The UN General Assembly’s 2024 resolution on AI likewise emphasizes safe, secure and trustworthy systems for sustainable development, while the Secretary-General’s guidance on human rights due diligence requires oversight across the lifecycle of digital technology use.
The High-level Advisory Body’s report, Governing AI for Humanity, reinforces the case for globally inclusive governance that protects human rights while enabling innovation (United Nations, 2024; United Nations General Assembly, 2024; United Nations Secretary-General, 2024; United Nations Secretary-General’s High-level Advisory Body on Artificial Intelligence, 2024).
These principles are not external constraints on innovation. They are what make innovation socially legitimate in the first place.
Agentic AI may indeed become a defining infrastructure of the digital age. But before we celebrate its autonomy, we need to confront its central asymmetry: a system can appear remarkably capable while remaining fundamentally uncomprehending. That gap between capability and comprehension is where many of the most serious risks reside.
This is why, in “AI alignment”—a now-critical branch of AI research—the approach of fine-tuning AI to align with human values is fundamentally consistent with the methods once used to push the boundaries of AI capabilities, such as reinforcement learning, supervised fine-tuning, and preference optimization (Ouyang et al., 2022; Longpre et al., 2023; Rafailov et al., 2023).
If AI agents are to support human flourishing rather than undermine it, the path forward is not unlimited agency. It is well-governed agency — constrained by design, accountable in operation and aligned with the values of the institutions and communities it is meant to serve (UNESCO, 2021; United Nations, 2024; United Nations Secretary-General, 2024).
References
Ashwini K. P. (2024). Contemporary forms of racism, racial discrimination, xenophobia and related intolerance: Report of the Special Rapporteur on contemporary forms of racism, racial discrimination, xenophobia and related intolerance, Ashwini K.P. (A/HRC/56/68). United Nations Human Rights Council. https://www.ohchr.org/en/documents/thematic-reports/ahrc5668-contemporary-forms-racism-racial-discrimination-xenophobia-and
Bang, A. (2026, February 4). AI agent goes rogue, spamming OpenClaw user with 500 messages. Bloomberg. https://www.bloomberg.com/news/articles/2026-02-04/openclaw-s-an-ai-sensation-but-its-security-a-work-in-progress
Bort, J. (2026, February 23). A Meta AI security researcher said an OpenClaw agent ran amok on her inbox. TechCrunch. https://techcrunch.com/2026/02/23/a-meta-ai-security-researcher-said-an-openclaw-agent-ran-amok-on-her-inbox/
Debenedetti, E., Zhang, J., Balunovic, M., Beurer-Kellner, L., Fischer, M., & Tramèr, F. (2024). Agentdojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents. Advances in Neural Information Processing Systems, 37, 82895-82920.
Gong, H., Li, C., Chang, R., & Shen, W. (2025). Secure and Efficient Access Control for Computer-Use Agents via Context Space. arXiv preprint arXiv:2509.22256.
International Telecommunication Union. (2025). The annual AI governance report 2025: Steering the future of AI. https://www.itu.int/pub/T-AI4G-AI4GOOD-2025-3/
Longpre, S., Hou, L., Vu, T., Webson, A., Chung, H. W., Tay, Y., ... & Roberts, A. (2023, July). The flan collection: Designing data and methods for effective instruction tuning. In International conference on machine learning (pp. 22631-22648). PMLR.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., ... & Lowe, R. (2022). Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35, 27730-27744.
Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., & Finn, C. (2023). Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36, 53728-53741.
UNESCO. (2021). Recommendation on the ethics of artificial intelligence. https://www.unesco.org/en/legal-affairs/recommendation-ethics-artificial-intelligence
United Nations. (2024). Global digital compact. https://www.un.org/global-digital-compact/sites/default/files/2024-09/Global%20Digital%20Compact%20-%20English_0.pdf
United Nations General Assembly. (2024). Seizing the opportunities of safe, secure and trustworthy artificial intelligence systems for sustainable development (A/RES/78/265). https://digitallibrary.un.org/record/4043244/files/A_RES_78_265-EN.pdf
United Nations Secretary-General. (2024). Human rights due diligence for digital technology use: Guidance of the Secretary-General. https://www.ohchr.org/en/documents/tools-and-resources/human-rights-due-diligence-digital-technology-use-guidance-secretary
United Nations Secretary-General’s High-level Advisory Body on Artificial Intelligence. (2024). Governing AI for humanity: Final report. United Nations. https://www.un.org/sites/un2.un.org/files/governing_ai_for_humanity_final_report_en.pdf
Wang, Y., Zhong, W., Huang, Y., Shi, E., Yang, M., Chen, J., ... & Zheng, Z. (2025). Agents in software engineering: Survey, landscape, and vision. Automated Software Engineering, 32(2), 70.
Wang, L., Ma, C., Feng, X., Zhang, Z., Yang, H., Zhang, J., ... & Wen, J. (2024). A survey on large language model based autonomous agents. Frontiers of Computer Science, 18(6), 186345.
Zhan, Q., Liang, Z., Ying, Z., & Kang, D. (2024, August). Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents. In Findings of the Association for Computational Linguistics: ACL 2024 (pp. 10471-10506).
Zhang, H., Huang, J., Mei, K., Yao, Y., Wang, Z., Zhan, C., Wang, H., & Zhang, Y. (2025). Agent Security Bench (ASB): Formalizing and benchmarking attacks and defenses in LLM-based agents. In The thirteenth international conference on learning representations. OpenReview. https://openreview.net/forum?id=V4y0CpX4hK
Suggested citation: Jia An LIU., "Why Agentic AI Needs Boundaries Before Freedom," UNU Macau (blog), 2026-04-02, 2026, https://unu.edu/macau/blog-post/why-agentic-ai-needs-boundaries-freedom.



